|
I am a second-year PhD student at Simon Fraser University (SFU),
advised by Prof. Hao (Richard) Zhang and
Prof. Ali Mahdavi-Amiri.
I also completed my master's at SFU under Prof. Hao (Richard) Zhang.
Before joining SFU, I worked as a Senior Research Engineer at Staqu Technologies,
where I developed production-scale computer vision systems for image and video analytics. Earlier, during my bachelor's,
I worked with Prof. Ujjwal Bhattacharya
at Indian Statistical Institute (ISI), Kolkata and
Prof. Partha Pratim Roy
at Indian Institute of Technology (IIT) Roorkee on various
Computer Vision research problems.
My research lies at the intersection of Computer Vision and Computer Graphics, with a focus on multimodal generative modeling
for the controllable generation and understanding of visual content, including images, video, and 3D.
Email /
Google Scholar /
LinkedIn /
GitHub /
X (Twitter)
|

|
|
|
BACH: Blend-Aware Composition and Harmonization for Mesh Multi-Texturing
Sai Raj Kishore Perla,
Zhuo Ning,
Negar Hassanpour,
Hao (Richard) Zhang,
Ali Mahdavi-Amiri
Under Review, 2026
|
|
|
Advances in Neural 3D Mesh Texturing: A Survey
Sai Raj Kishore Perla,
Hao (Richard) Zhang,
Ali Mahdavi-Amiri
Eurographics STAR (State of The Art Reports), Computer Graph. Forum, 2026
Abstract /
GitHub /
arXiv /
Project Page /
BibTex
Texturing 3D meshes plays a vital role in determining the visual realism of digital objects and scenes.
Although recent generative 3D approaches based on Neural Radiance Fields and Gaussian Splatting can produce textured assets directly,
polygonal meshes remain the core representation across modeling, animation, visual effects, and gaming pipelines.
Neural 3D mesh texturing therefore continues to be an essential and active area of research.
In this survey, we present a comprehensive review of recent advances in neural 3D mesh texturing,
covering methods for texture synthesis, transfer, and completion. We first summarize key foundations in mesh geometry,
texture mapping, differentiable rendering, and neural generative models, and then organize the literature into a
unified taxonomy spanning early GAN-based methods to modern diffusion-based pipelines.
We further analyze common architectures and supervision strategies, review datasets and evaluation protocols,
and discuss emerging applications, practical/commercial systems, and open challenges.
Together, these insights provide a structured perspective on the current landscape and help guide future developments
in learning-based 3D mesh texturing.
@article{perla2026NeuralMeshTexSurvey,
title = {Advances in Neural 3D Mesh Texturing: A Survey},
author = {Perla, Sai Raj Kishore and Zhang, Hao and Mahdavi-Amiri, Ali},
journal = {Eurographics STAR (State of The Art Reports), Computer Graphics Forum},
pages = {e70392},
year = {2026},
doi = {https://doi.org/10.1111/cgf.70392},
url = {https://sairajk.github.io/neural-mesh-texturing},
}
|
|
|
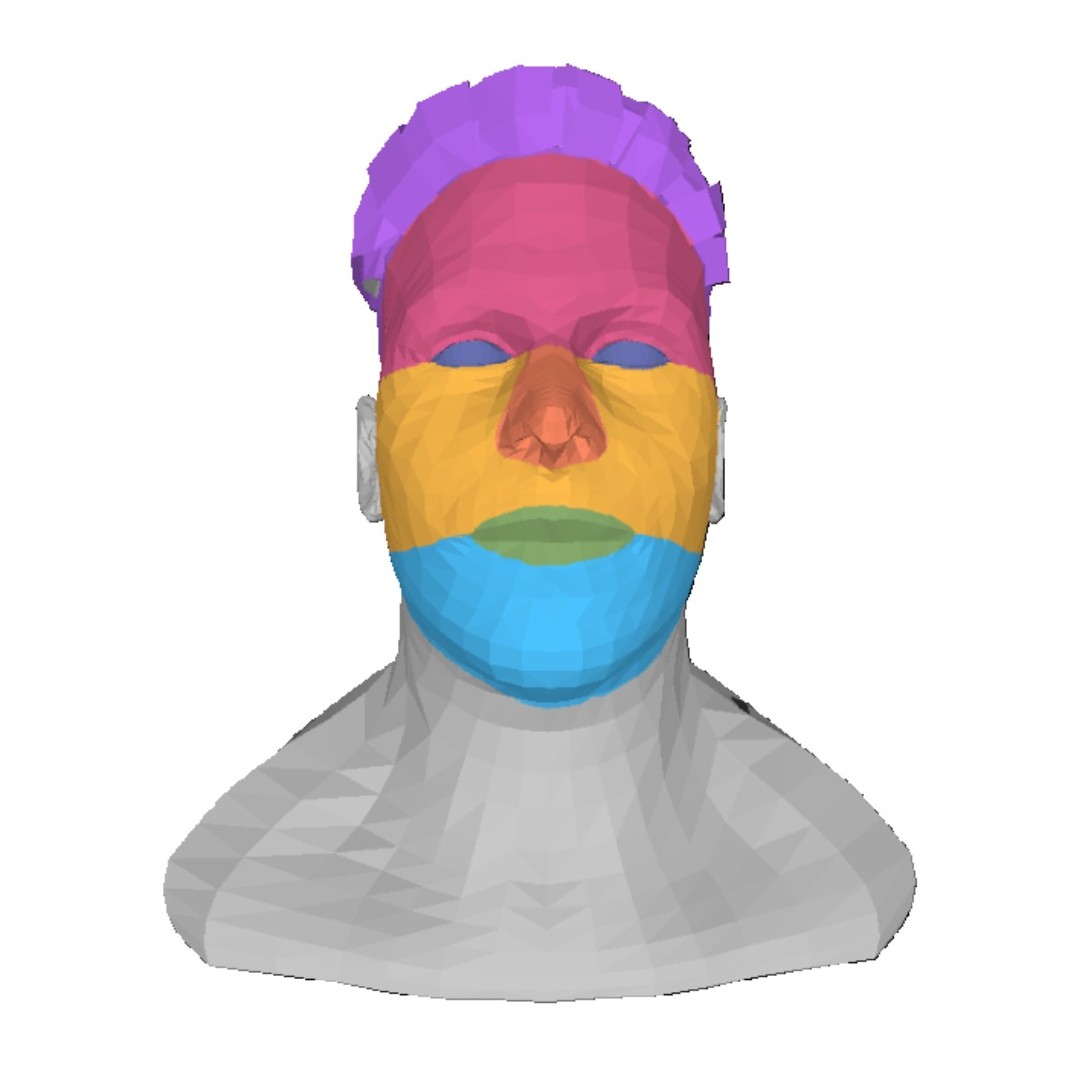
ASIA: Adaptive 3D Segmentation using Few Image Annotations
Sai Raj Kishore Perla,
Aditya Vora,
Sauradip Nag,
Ali Mahdavi-Amiri,
Hao (Richard) Zhang
SIGGRAPH Asia, 2025
3DV (Nectar Track), 2026
Abstract /
Code /
arXiv /
Project Page /
BibTex
We introduce ASIA (Adaptive 3D Segmentation using few Image Annotations), a novel framework that enables segmentation of possibly non-semantic and non-text-describable “parts” in 3D. Our segmentation is controllable through a few user-annotated in-the-wild images, which are easier to collect than multi-view images, less demanding to annotate than 3D models, and more precise than potentially ambiguous text descriptions. Our method leverages the rich priors of text-to-image diffusion models, such as Stable Diffusion (SD), to transfer segmentations from image space to 3D, even when the annotated and target objects differ significantly in geometry or structure. During training, we optimize a text token for each segment and fine-tune our model with a novel cross-view part correspondence loss. At inference, we segment multi-view renderings of the 3D mesh, fuse the labels in UV-space via voting, refine them with our novel Noise Optimization technique, and finally map the UV-labels back onto the mesh. ASIA provides a practical and generalizable solution for both semantic and non-semantic 3D segmentation tasks, outperforming existing methods by a noticeable margin in both quantitative and qualitative evaluations.
@article{perla2025asia,
title={{ASIA}: Adaptive 3D Segmentation using Few Image Annotations},
author = {Perla, Sai Raj Kishore and Vora, Aditya and Nag, Sauradip, Mahdavi-Amiri, Ali and Zhang, Hao},
journal = {SIGGRAPH Asia Conference Papers},
publisher = {ACM New York, NY, USA},
year = {2025},
doi = {10.1145/3757377.3763821},
url = {https://github.com/sairajk/asia},
}
|
|
|
EASI-Tex: Edge-Aware Mesh Texturing from Single Image
Sai Raj Kishore Perla,
Yizhi Wang,
Ali Mahdavi-Amiri,
Hao (Richard) Zhang
ACM Transactions on Graphics (Proceedings of SIGGRAPH), 2024
Abstract /
Code /
arXiv /
Project Page /
BibTex
We present a novel approach for single-image mesh texturing, which employs a diffusion model with judicious conditioning to seamlessly transfer an object's texture from a single RGB image to a given 3D mesh object. We do not assume that the two objects belong to the same category, and even if they do, there can be significant discrepancies in their geometry and part proportions. Our method aims to rectify the discrepancies by conditioning a pre-trained Stable Diffusion generator with edges describing the mesh through ControlNet, and features extracted from the input image using IP-Adapter to generate textures that respect the underlying geometry of the mesh and the input texture without any optimization or training. We also introduce Image Inversion, a novel technique to quickly personalize the diffusion model for a single concept using a single image, for cases where the pre-trained IP-Adapter falls short in capturing all the details from the input image faithfully. Experimental results demonstrate the efficiency and effectiveness of our edge-aware single-image mesh texturing approach, coined EASI-Tex, in preserving the details of the input texture on diverse 3D objects, while respecting their geometry.
@article{perla2024easitex,
title={EASI-Tex: Edge-Aware Mesh Texturing from Single Image},
author = {Perla, Sai Raj Kishore and Wang, Yizhi and Mahdavi-Amiri, Ali and Zhang, Hao},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH)},
publisher = {ACM New York, NY, USA},
year = {2024},
volume = {43},
number = {4},
articleno = {40},
doi = {10.1145/3658222},
url = {https://github.com/sairajk/easi-tex},
}
|
|
|
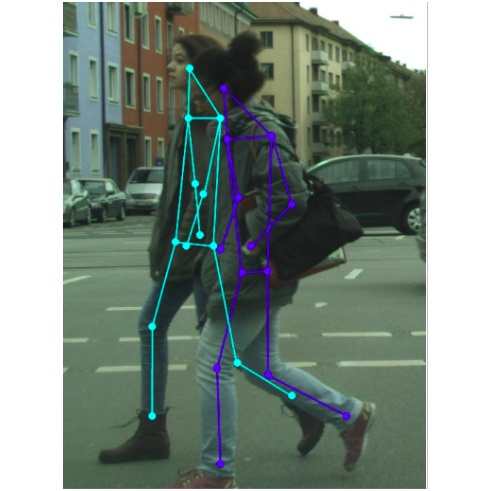
An End-To-End Framework For Pose Estimation of Occluded Pedestrians
Sai Raj Kishore Perla*,
Sudip Das*,
Ujjwal Bhattacharya
International Conference on Image Processing (ICIP), 2020
Abstract /
BibTex
Pose estimation in the wild is a challenging problem, particularly in situations of(i) occlusions of varying degrees, and (ii) crowded outdoor scenes. Most of the existing studies of pose estimation did not report the performance in similar situations. Moreover, pose annotations for occluded parts of the human figures have not been provided in any of the relevant standard datasets, which in turn creates further difficulties to the required studies for pose estimation of the entire Figure for occluded humans. Well known pedestrian detection datasets such as CityPersons contains samples of outdoor scenes but it does not include pose annotations. Here we propose a novel multi-task framework for end-to-end training towards the entire pose estimation of pedestrians including in situations of any kind of occlusion. To tackle this problem, we make use of a pose estimation dataset, MS-COCO, and employ unsupervised adversarial instance-level domain adaptation for estimating the entire pose of occluded pedestrians. The experimental studies show that the proposed framework outperforms the SOTA results for pose estimation, instance segmentation and pedestrian detection in cases of heavy occlusions (HO) and reasonable + heavy occlusions (R+HO) on the two benchmark datasets.
@INPROCEEDINGS{9191147,
author={Das, Sudip and Perla, Sai Raj Kishore and Bhattacharya, Ujjwal},
booktitle={IEEE International Conference on Image Processing (ICIP)},
title={An End-To-End Framework For Pose Estimation of Occluded Pedestrians},
year={2020},
pages={1446-1450},
doi={10.1109/ICIP40778.2020.9191147}
}
|
|
|
ClueNet: A Deep Framework for Occluded Pedestrian Pose Estimation
Sai Raj Kishore Perla*,
Sudip Das*,
Partha Sarathi Mukherjee,
Ujjwal Bhattacharya
British Machine Vision Conference (BMVC), 2019
Abstract /
BibTex
Pose estimation of a pedestrian helps to gather information about the current activity or the instant behaviour of the subject. Such information is useful for autonomous vehicles, augmented reality, video surveillance, etc. Although a large volume of pedestrian detection studies are available in the literature, detection of the same in situations of significant occlusions still remains a challenging task. In this work, we take a step further to propose a novel deep learning framework, called ClueNet, to detect as well as estimate the entire pose of occluded pedestrians in an unsupervised manner. ClueNet is a two stage framework where the first stage generates visual clues for the second stage to accurately estimate the pose of occluded pedestrians. The first stage employs a multi-task network to segment the visible parts and predict a bounding box enclosing the visible and occluded regions for each pedestrian. The second stage uses these predictions from the first stage for pose estimation. Here we propose a novel strategy, called Mask and Predict, to train our ClueNet to estimate the pose even for occluded regions. Additionally, we make use of various other training strategies to further improve our results. The proposed work is first of its kind and the experimental results on CityPersons and MS COCO datasets show the superior performance of our approach over existing methods.
@article{kishore2019cluenet,
title={ClueNet: A Deep Framework for Occluded Pedestrian Pose Estimation},
author={Perla, Sai Raj Kishore and Das, Sudip and Mukherjee, Partha Sarathi and Bhattacharya, Ujjwal},
booktitle={30th British Machine Vision Conference {BMVC}},
year={2019}
}
|
|
|
Handwriting Recognition in Low-Resource Scripts Using Adversarial Learning
Ayan Kumar Bhunia,
Abhirup Das,
Ankan Kumar Bhunia,
Sai Raj Kishore Perla,
Partha Pratim Roy
Conference on Computer Vision and Pattern Recognition (CVPR), 2019
Abstract /
Code /
arXiv /
BibTex
Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten text possessing irregular and complex shapes. The design of deep neural network models makes it necessary to extend training datasets in order to introduce variations and increase the number of samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the existing literature comprises preprocessing strategies which are seldom sufficient to cover all possible variations. We propose an Adversarial Feature Deformation Module (AFDM) that learns ways to elastically warp extracted features in a scalable manner. The AFDM is inserted between intermediate layers and trained alternatively with the original framework, boosting its capability to better learn highly informative features rather than trivial ones. We test our meta-framework, which is built on top of popular word-spotting and word-recognition frameworks and enhanced by AFDM, not only on extensive Latin word datasets but also on sparser Indic scripts. We record results for varying sizes of training data, and observe that our enhanced network generalizes much better in the low-data regime; the overall word-error rates and mAP scores are observed to improve as well.
@InProceedings{Bhunia_2019_CVPR,
author = {Bhunia, Ayan Kumar and Das, Abhirup and Bhunia, Ankan Kumar and Perla, Sai Raj Kishore and Roy, Partha Pratim},
title = {Handwriting Recognition in Low-Resource Scripts Using Adversarial Learning},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
|
|
|
User Constrained Thumbnail Generation Using Adaptive Convolutions
Sai Raj Kishore Perla,
Ayan Kumar Bhunia,
Shovozit Ghose,
Partha Pratim Roy
Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2019
(Oral)
Abstract /
Code /
arXiv /
BibTex
Thumbnails are widely used all over the world as a preview for digital images. In this work we propose a deep neural framework to generate thumbnails of any size and aspect ratio, even for unseen values during training, with high accuracy and precision. We use Global Context Aggregation (GCA) and a modified Region Proposal Network (RPN) with adaptive convolutions to generate thumbnails in real time. GCA is used to selectively attend and aggregate the global context information from the entire image while the RPN is used to generate candidate bounding boxes for the thumbnail image. Adaptive convolution eliminates the difficulty of generating thumbnails of various aspect ratios by using filter weights dynamically generated from the aspect ratio information. The experimental results indicate the superior performance of the proposed model 1 over existing state-of-the-art techniques.
@inproceedings{kishore2019user,
title={User Constrained Thumbnail Generation Using Adaptive Convolutions},
author={Perla, Sai Raj Kishore and Bhunia, Ayan Kumar and Ghose, Shuvozit and Roy, Partha Pratim},
booktitle={IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1677--1681},
year={2019},
organization={IEEE}
}
|
|
|
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Ayan Kumar Bhunia,
Sai Raj Kishore Perla,
Pranay Mukherjee,
Abhirup Das,
Partha Pratim Roy
Winter Conference on Applications of Computer Vision (WACV), 2019
Abstract /
arXiv /
BibTex
With the large scale explosion of images and videos over the internet, efficient hashing methods have been developed to facilitate memory and time efficient retrieval of similar images. However, none of the existing works use hashing to address texture image retrieval mostly because of the lack of sufficiently large texture image databases. Our work addresses this problem by developing a novel deep learning architecture that generates binary hash codes for input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which takes a texture patch as input and outputs an enlarged view of the texture by injecting newer texture content. Thus it signifies that the TSN encodes the learnt texture specific information in its intermediate layers. In the next stage, a second network gathers the multi-scale feature representations from the TSN’s intermediate layers using channel-wise attention, combines them in a progressive manner to a dense continuous representation which is finally converted into a binary hash code with the help of individual and pairwise label information. The new enlarged texture patches from the TSN also help in data augmentation to alleviate the problem of insufficient texture data and are used to train the second stage of the network. Experiments on three public texture image retrieval datasets indicate the superiority of our texture synthesis guided hashing approach over existing state-of-the-art methods.
@inproceedings{bhunia2019texture,
title={Texture synthesis guided deep hashing for texture image retrieval},
author={Bhunia, Ayan Kumar and Perla, Sai Raj Kishore and Mukherjee, Pranay and Das, Abhirup and Roy, Partha Pratim},
booktitle={IEEE Winter Conference on Applications of Computer Vision (WACV)},
pages={609--618},
year={2019},
organization={IEEE}
}
|
|
|
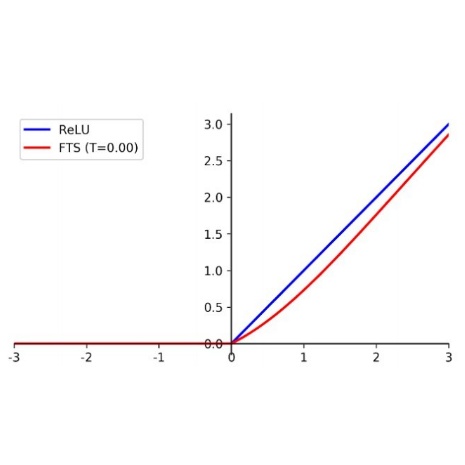
Flatten-T Swish: A thresholded ReLU-Swish-like Activation Function for Deep Learning
Hock Hung Chieng,
Noorhaniza Wahid,
Ong Pauline,
Sai Raj Kishore Perla
International Journal of Advances in Intelligent Informatics (IJAIN), 2018
(Best Paper Award)
Abstract /
Code /
arXiv /
BibTex
Activation functions are essential for deep learning methods to learn and perform complex tasks such as image classification. Rectified Linear Unit (ReLU) has been widely used and become the default activation function across the deep learning community since 2012. Although ReLU has been popular, however, the hard zero property of the ReLU has heavily hindering the negative values from propagating through the network. Consequently, the deep neural network has not been benefited from the negative representations. In this work, an activation function called Flatten-T Swish (FTS) that leverage the benefit of the negative values is proposed. To verify its performance, this study evaluates FTS with ReLU and several recent activation functions. Each activation function is trained using MNIST dataset on five different deep fully connected neural networks (DFNNs) with depth vary from five to eight layers. For a fair evaluation, all DFNNs are using the same configuration settings. Based on the experimental results, FTS with a threshold value, T=-0.20 has the best overall performance. As compared with ReLU, FTS (T=-0.20) improves MNIST classification accuracy by 0.13%, 0.70%, 0.67%, 1.07% and 1.15% on wider 5 layers, slimmer 5 layers, 6 layers, 7 layers and 8 layers DFNNs respectively. Apart from this, the study also noticed that FTS converges twice as fast as ReLU. Although there are other existing activation functions are also evaluated, this study elects ReLU as the baseline activation function.
@article{IJAIN249,
author = {Hock Chieng and Noorhaniza Wahid and Ong Pauline and Sai Raj Kishore Perla},
title = {Flatten-T Swish: a thresholded ReLU-Swish-like activation function for deep learning},
journal = {International Journal of Advances in Intelligent Informatics},
volume = {4},
number = {2},
year = {2018},
pages = {76--86},
doi = {10.26555/ijain.v4i2.249},
url = {http://ijain.org/index.php/IJAIN/article/view/249}
}
|
|